1 Einleitung
1.1 KI als Hilfe für die Lehre
!!!!
Wie kann uns generative künstliche Intelligenz (KI) in der Lehre helfen? Hoffnung besteht hier für zwei typische Probleme: Erstens haben Studierende individuelle Bedürfnisse, aber wir haben nur begrenzte Zeit, auf diese einzugehen. Wie können wir Einzelne möglichst intensiv fördern, ohne vor Arbeit unterzugehen? Zweitens ist der Aufwand gerade für effektive Lehrmethoden oft sehr hoch, so etwa für häufige niedrigschwellige Tests oder individuelles Feedback zu Studienarbeiten (Brown et al., 2014; s. etwa Hattie, 2023, Kap.13). Wer lehrt, fühlt sich aus Zeit- und Stoffdruck oft gezwungen, Abstriche von idealen Lehrsetups zu machen (Henderson & Dancy, 2007; Schmidt & Tippelt, 2005, S.104–105). Gerade Lehrmethoden, die didaktisch sinnvoll, aber mit höherem Aufwand verbunden sind, drohen dabei auf der Strecke zu bleiben (s. etwa Dunlosky et al., 2013; Roediger & Pyc, 2012).
Für die Lehre erschließen sich durch die großen KI-Sprachmodelle (LLM = Large Language Models) neue Möglichkeiten. Sie sind, wie es eine Analyse des MIT Professors Andrew McAfee auf den Punkt bringt, „generally faster“ (McAfee, 2024). Lehrende können mit KI-Unterstützung etwa deutlich schneller eine Recherche durchführen, ein Set von Übungsaufgaben erstellen, mehrere Anwendungsbeispiele pro Konzept hinzufügen, Quizfragen zur schnellen Lernüberprüfung generieren oder mit den Studierenden Rollenspiele durchführen (Meincke et al., 2024; E. R. Mollick & Mollick, 2023). Der Berg ist noch da, aber mit dem E-Bike kommt man weiter.

1.2 Was 2026 möglich ist: Praktische Beispiele für Recherche, Übungsaufgaben, Erklärungen
“KI nutzen” heißt Anfang 2026 nicht mehr nur “chatten mit dem Bot”, sondern Delegation an Agenten (E. Mollick, 2026): Man delegiert Aufgaben, die KI nutzt Werkzeuge und arbeitet mehrstufig, prüft also selbstständig Zwischenergebnisse. Praktisch unterschieden wir dabei drei Ebenen: Modelle (das Sprachmodell, z.B. GPT 5.2), Apps (die Oberfläche, z.B. die Texteingabe im Browser bei Chat GPT) und Harnesses („Arbeitsgeschirr“ oder Werkzeugkasten, etwa Web-Recherche, Zugriff auf einen Ordner mit Daten oder die Fähigkeit zum Rechnen mit Programmiersprachen wie Python). Wichtig für die Lehre: Wenig Kosten heißt oft auch wenig(er) Nutzen (“No such thing as a free lunch”, hört man die Ökonomen murmeln…(Friedman & Friedman, 1975)). Viele Plattformen locken Nutzer in kostenlose Tarife oder per „Auto“-Auswahl in schwächere Modellvarianten, denen dann das iterative Vorgehen fehlt (reasoning), oft ohne oder nur mit sehr begrenztem Harness-Werkzeugkasten. Das wirkt zunächst „gut genug“, erhöht aber das Risiko von Fehlern, veralteten Informationen und oberflächlichem Denken. Für die Lehre heißt das: Wer GenAI als Lehrassistenz nutzen will, sollte bewusst eine starke Modellvariante und ein passendes Harness wählen – und Ergebnisse grundsätzlich didaktisch gegenprüfen.
Schauen wir uns einige praktische Beispiele an, was mit schlauen Modellen und gut gefülltem Werkzeugkasten mittlerweile möglich ist. Wir suchen aktuelle Fallstudien zu Lieferketten-Problemen. Als Recherche-Hiwi sucht das Sprachmodell auf akademischen Blogs und Fachzeitschriften nach aktuellen Beispielen.

Solche Suchen führen Sprachmodelle mittlerweile in mehreren Schritten durch. Hier sehen wir den “Denkprozess”.

Hier das Ergebnis: Ein erster ausformulierter Bericht von 13 Seiten nach ca. 5 Minuten Recherche. Die Abbildung zeigt den Auszug mit der tabellarischen Zusammenfassung der Forschungsartikel.

Wie kann man Konzepte einfach und mit Beispielen erklären? Wir bitten ChatGPT um Vorschläge zu zwei Konzepten aus der Wissenschaftstheorie: Der Duhem-Quine-These, die beschreibt, warum Wissenschaft nur graduell, mosaik-bauend zu Erkenntnissen kommen kann, und Mayos Konzept der “Strengen Tests” (severe testing), nach denen man wissenschaftliche Aussagen graduell auf ihre Belastbarkeit bewerten kann.

Wie könnte man das in einem Test abfragen? Auch hierzu bitten wir ChatGPT (5.2) um Vorschläge.

Ende 2025 generieren die starken Sprachmodelle professionelle Folien-Präsentationen in Sekunden. Sprachmodelle wie Googles Gemini können mittlerweile auch Text in Bildern erstellen (Willison, 2025b) und damit auch komplexe Infografiken (und Folien). Das Sprachmodell Claude liefert eine Beschreibung (‘Skill’) von 3500 Wörtern mit, die dem Sprachmodell genau erklärt, wie es Schritt für Schritt eine PowerPoint-Präsentation erstellt und testet (Anthropic, 2025). Weiter unten zeigen wir, wie so ein Skill etwa bei der Erstellung komplexer Dokumente (Hausarbeiten!) hilft.
Grafisch ansprechende Präsentationen kosten Zeit – und Brillanz als Grafiker gehört vielleicht auch nicht zu den Kernkompetenzen von Lehrenden. Wir bitten daher Gemini (NotebookLM) und Claude, uns basierend auf Überblicksartikeln zwei Präsentationen zu erstellen: Eine zur Frage, welche Lerntechniken für Studierende besonders gut funktionieren (s. Kapitel 2) und die zweite zur Frage, welche Best-Practices es gibt, Aufgabenstellungen mit der intensiven Nutzung von GenAI zu verbinden (s. ?sec-prompts).
Zu integrierten Aufgaben mit GenAI liefert uns das Sprachmodell nach wenigen Minuten 15 sehr schicke Folien (NotebookLM, basierend auf 13 Quellen-PDFs).

Zu Lerntechniken erhielten wir nach etwa 5 Minuten basierend auf einem Fachartikel 8 professionelle Folien (mit kleineren Formatierungsfehlern, etwa Zeilenumbrüchen).

1.3 Nutzung von GenAI in der Forschung
Immer mehr Aspekte von typischen Forschungstätigkeiten – ein zentraler Ausbildungsinhalt der Hochschulen – können von der KI übernommen werden und zwar auf hohem Niveau. Vorbei sind die Zeiten, da wir über banale KI-Texte nur lächelten. Ein Überblicksartikel des Forschers Anton Korinek im renommierten Journal of Economic Literature vom Dezember 2024 fasst die deutlich höhere Qualität des Outputs zusammen: „die derzeitige Generation von LLMs ist in hohem Maße in der Lage, die wichtigsten Erkenntnisse von Forschungsarbeiten zu verarbeiten” (Korinek, 2024, S.3, Übersetzung RB mit DeepL).
Professionelle Forscher sind hier teils schon weiter. Eine schöne visuelle Verdeutlichung davon, was jetzt möglich ist, findet sich hier: Eine Visualisierung von über 6000 Konferenzbeiträgen, die jeweils zusammengefasst werden und denen durch ein Sprachmodell eine Erklärung in einfacher Sprache beigefügt wurde (“explain-it-like-I’m-5”): Hier kann man das interaktiv ausprobieren: https://jalammar.github.io/assets/neurips_2025.html.

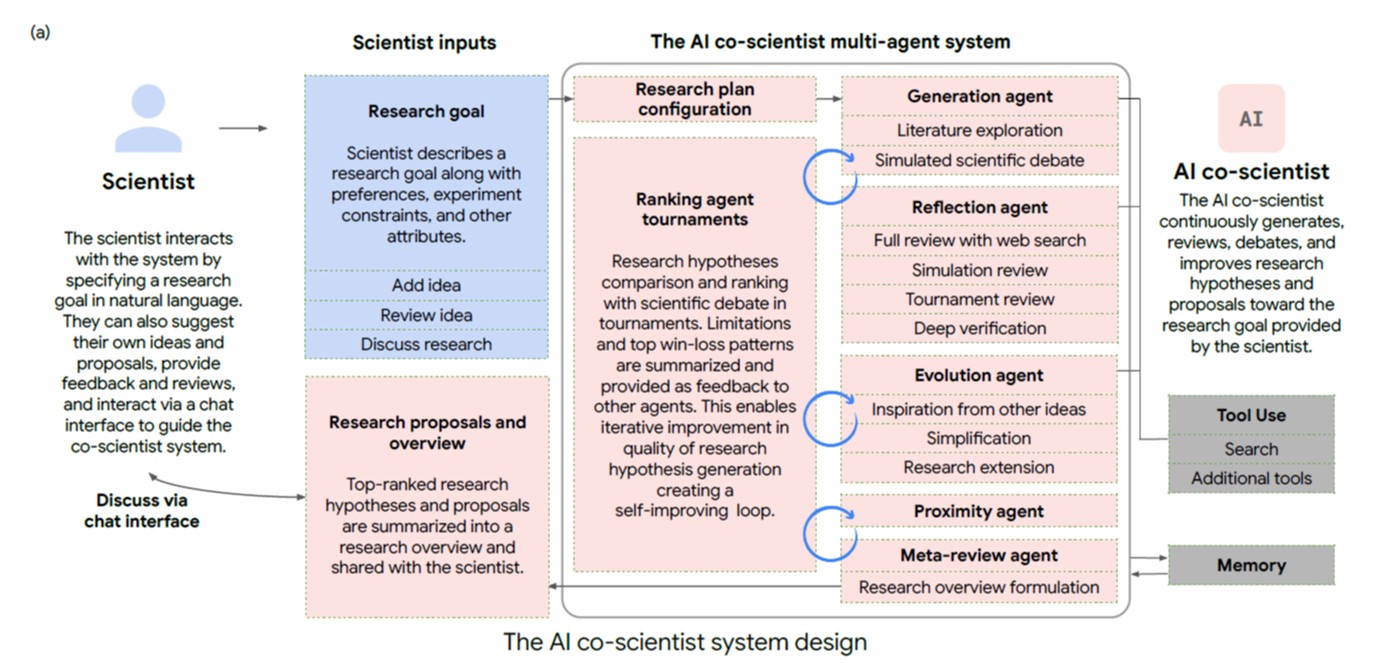
Wie kann GenAI uns bei der Forschung direkt unterstützen? Google demonstrierte 2025 ein mehrstufiges Modell für die Pharma-Forschung (‘AI co-scientist’), das den Forschenden zeitintensive Zwischenschritte abnimmt (Gottweis et al., 2025) (s. Abbildung 1.10). OpenAI zeigte Ende 2023 schon in einem ausführlichen Bericht eine Vielzahl möglicher Hilfsanwendungen im Wissenschaftsbereich. Mit deutlichen Warnhinweisen (speziell wegen selbstbewusst vertretenen Halluzinationen) aber auch teils erstaunlich hoher Qualität (Bubeck et al., 2023). Auch im Peer-Review werden zunehmend Sprachmodelle eingesetzt – mit allen Vor- und Nachteilen, die das mit sich bringt (Naddaf, 2025). Wie wir in den späteren Kapiteln sehen, experimentieren Hochschulen weltweit intensiv mit den neuen Möglichkeiten für Lehre und Forschung.
Ende 2025 hat sich der potenzielle Mehrwert (und speziell Zeitgewinn) bei fachgemäßer Nutzung noch einmal erweitert. Ein aktueller Bericht (November 2025) von OpenAI stellt eine Reihe von Fallstudien dar, wie Forschende starke Sprachmodelle einsetzen (Bubeck et al., 2025). Die Quelle der Ergebnisse ist natürlich nicht neutral (OpenAI), die Ergebnisse sind aber m. E. mit Blick auf die eigene Nutzungserfahrung sehr plausibel: Als Mehrwert wird häufig eine außerordentliche Zeitersparnis bei Routinetätigkeiten genannt, speziell bei der Nutzung von Verfahren und Wissensquellen, die die Forscher zwar bewerten können, deren Aneignung aber ohne die Hilfe der Sprachmodelle deutlich länger dauern würde. Dies ist sehr wertvoll und wird die Verbreitung solcher Tools treiben. Wir sehen in den Einzelberichten aber auch klare Warnsignale: Wenn man die Zwischenergebnisse mangels Fachkenntnis nicht kritisch hinterfragen kann, ist die Wahrscheinlichkeit hoch, Fehler zu übernehmen. Auch starke Sprachmodelle vertreten sehr überzeugend falsche Ergebnisse und Ansätze. Nur durch Fachwissen haben Nutzer die erforderlichen Bewertungsmuster. Erst durch eigenes Fachwissen und durch Erfahrung im kritischen Umgang mit dem Tool entsteht der Mehrwert. Man muss sozusagen das Terrain kennen und lernen, wie man den Sportwagen Sprachmodell fahren muss. So können dann auch Unfälle besser vermieden werden.
Am Ende dieses Kapitels haben wir aus einer aktuellen Studie Schlaglichter zu Forschungs-Versuchen aus den verschiedenen Disziplinen zusammengestellt (Bubeck et al., 2025) (siehe Kapitel 1.8).
Wie ein Laie im Cockpit eines Verkehrsflugzeugs fällt es Lehrenden teils schwer zu entscheiden, welche der neuen Möglichkeiten sinnvoll für die eigene Lehre sind. Zunächst gibt es immer wieder Hype-Zyklen: Virtuelle Realität, Blockchain, Roboter, Internet der Dinge… (Allen & Edelson, 2024), viel wurde schon ins Rampenlicht gestellt und dann wieder vergessen. Hersteller und Beratungen bewerben und ‘hypen’ regelmäßig neue Technologien für die Lehre, so dass wir schon aus Selbstschutz eine gewisse Grundskepsis mitbringen sollten, ob ein neuer technischer Zugang wirklich auch didaktischen Nutzen bringt (für eine wirkungsbasierte Übersicht von Technologien s. etwa Hattie, 2023, Kap.14). Lehrende sind außerdem paradoxen Spannungen zwischen den Identitäten als Experten und Innovatoren ausgesetzt (Fischer & Dobbins, 2024): Ausgestrahlte Kompetenz ist einerseits Teil ihres Wertversprechens, was zur Abwehr ungewohnter Technologien einlädt. Andererseits sollen Lehrende auch zu Neugier und Innovation anleiten und insofern den Umgang mit neuen, auch für die Lehrenden selbst ungewohnten Technologien erleichtern.

1.4 Aktuelle Weiterentwicklungen der Sprachmodelle
2025 lernen die großen Sprachmodelle noch besser „nachzudenken“ – sogenannte „Reasoning“-Modelle werden breit verfügbar. Aus didaktischer Sicht ist das auch deshalb interessant, weil man Lernenden jetzt Denkstrategien vorführen kann, speziell Hypothesenbildung und Prüfung (etwa (Brown et al., 2014), S. 90–94, “generative learning”, oder die Studien von Willemain zur Modellierung von Problemen durch Experten (Willemain, 1994, 1995)). Ein neuer Ansatzpunkt zur Verbesserung der Ergebnisse wird hier genutzt (Grootendorst, 2025): Statt (nur) mehr Ressourcen in das Training immer komplexerer Modelle zu investieren (train-time compute), werden die Modelle jetzt dazu angehalten, länger „nachzudenken“, bevor sie ein Ergebnis anbieten (test-time compute). Hinter diesem „besseren Nachdenken“ stehen zwei Prinzipien (Grootendorst, 2025; Snell et al., 2024): Die Sprachmodelle werden einerseits instruiert, schrittweise vorzugehen (Input-Verbesserung der Vorschlagsverteilung) und andererseits dazu angehalten, die eigenen Antworten zu prüfen (Output-Verbesserung, Verifizierer). Die Sprachmodelle führen insofern jetzt teils selbstständig Prüfschritte durch, die man früher durch komplexe Prompts induziert hätte. Ende 2025 sehen wir in der Konsequenz, dass die Sprachbots immer selbstständiger werden, man spricht vom „Agentic Turn“ (E. R. Mollick, 2025a; Steinberger, 2025; Willison, 2025a): Als Nutzer solcher Reasoning Modelle verbringen wir jetzt weniger Zeit damit, über die ‚Zaubersprüche‘ einzelner Prompts nachzudenken und mehr Zeit in ‚Mitarbeitergesprächen‘ – Anleitung und Kritik der digitalen „Agenten“ – Sprachmodelle, die selbstständig und auf hohem Niveau mehrere Arbeitsschritte durchführen. Insgesamt steigt seit 2023 die Qualität der Aufgaben, die Sprachmodelle erledigen können, rasant. Empirische Untersuchungen zeigen, dass die Sprachmodelle immer längere Aufgaben auf hohem Niveau erledigen können (Kwa et al., 2025).
Die neuen Modelle sind außerdem günstiger und effizienter geworden: die Kosten pro Interaktion sind stark gesunken. Illustratives Beispiel: Eine Million Token kosteten mit GPT-4 noch 50 Dollar, jetzt nur noch 14 Cent (InvertedStone, 2025; E. R. Mollick, 2025b). Das Modell halluziniert (weiterhin, also Vorsicht, aber) deutlich seltener als seine Vorgänger: OpenAI gibt hier ca. 1 % Halluzinationen der Antworten statt ca. 5 % bei Vorgängermodellen (o3, 4o) an, je nach Komplexität der Frage und erlaubter „Bedenkzeit“ (OpenAI, 2025b).
Weiterhin hat sich die Internetsuche mit LLMs deutlich verbessert. Während man früher noch oft über sinnlose oder erfundene Ergebnisse lachte, stellt die Suche von ChatGPT, Google/Gemini oder speziellen Suchanbietern wie Perplexity mittlerweile eine große Zeitersparnis dar: „a useful tool to provide up-to-date answers to questions that are grounded in facts found on the internet, together with the requisite citations—a crucial capability for researchers“ (Korinek, 2024, S.3). Das gilt zunehmend für die stärksten allgemeinen Modelle und erst recht für Anbieter, die auf Forschungsrecherche (und Studierende) spezialisiert sind, wie Elicit oder Paperpal. Auch breite Internet-Recherchen und Textproduktionen sind zunehmend komplett delegierbar („deep research“), mit deutlichen Auswirkungen auf den Arbeitsprozess in der Wissensarbeit (s. etwa Schwarcz et al. (2025) für juristische Recherchen, Korinek (2024) für Ökonomie und Liang et al. (2025) für PR-Tätigkeiten).
Auch komplexe Texte können die Sprachmodelle mittlerweile erstellen, prüfen und verbessern. Wie weit sich das fortentwickelt hat, sehen wir am folgenden Beispiel: Einem vorgefertigten ‘Skill’ - einer detaillierten Ablaufbeschreibung zur Erstellung komplexer Texte (OpenAI (2025a); anthropic2025a; willison2025b).
Mit ‘Skills’ können wir dem Sprachmodell einen Block an sehr konkreten Anweisungen mitgeben. Zum Beispiel um komplexe längere Texte zu schreiben. Wie detailliert das ist, sehen wir hier am Beispiel des Skills “Co-Authoring”, der folgendes detailliert beschreibt:
1- Erfragt Meta-Informationen (Dokumenttyp, Zielgruppe, Zielsetzung) und integriert vorhandene Templates oder Dokumente.
2- Fordert den Nutzer zu einem “Info-Dump” auf und stellt anschließend gezielte Fragen, um Verständnis- und Kontextlücken zu schließen.
3- Erstellt eine initiale Dokumentenstruktur als bearbeitbares Artefakt (Datei) mit Platzhaltern.
4- Führt für jeden Abschnitt ein Brainstorming von Inhaltsoptionen durch und lässt den Nutzer auswählen, bevor der Text formuliert wird.
5- Erstellt den Entwurf für den jeweiligen Abschnitt und führt iterative Änderungen auf Basis präziser Nutzeranweisungen durch.
6- Simuliert Leserfragen (“Reader Testing”) mit einer kontextfreien Instanz, um logische Lücken, Unklarheiten oder fehlendes Vorwissen aufzudecken.
7- Korrigiert identifizierte Schwachstellen und führt eine abschließende Gesamtkohärenzprüfung durch.
Den kompletten Skill finden Sie hier: https://github.com/anthropics/skills/blob/main/skills/doc-coauthoring/SKILL.md
1.5 Wie nutzen Studierende und Lehrende GenAI?
Für Studierende sind GenAI Chatbots zum Standard für Informationssuche und Schreibaufgaben geworden: So berichten 92 % der befragten britischen Vollzeitstudierenden (n=1.041, Erhebung im Dezember 2024), dass sie KI-Tools wie ChatGPT regelmäßig verwenden, und 88 % geben an, solche Tools für Prüfungsleistungen („for assessments“) zu nutzen (Freeman, 2025). Deutsche Daten des CHE-Centrum für Hochschulentwicklung bestätigen dies: etwa zwei Drittel der Studierenden gaben Ende 2024 an, KI-Tools mindestens wöchentlich einzusetzen (Hüsch, Marc et al., 2025) (65 %, n=23.288 von 171 Hochschulen).
Wofür genau nutzen Studierende GenAI? Studierende berichten, dass sie sich am häufigsten Konzepte erklären lassen, Artikel zusammenfassen oder Ideen für Schreib- und Forschungsprojekte sammeln (Freeman, 2025). Nutzungsstudien zeigen sogar noch stärkeren Einsatz speziell für Schreibprojekte (s. Abbildung 1.12): Wie eine Auswertung von 1 Million anonymisierten Chats zwischen Usern mit Universitätskonto und dem Sprachmodell zeigt, verwenden Studierende die KI-Bots vor allem zum Erstellen neuer Inhalte und das Analysieren komplexer Themen, was höheren Ebenen der Bloomschen Taxonomie entspricht (s. Abbildung 1.13). Ein Großteil der befragten britischen Studierenden gibt an, Prüfungsleistungen durch GenAI zu unterstützen. Dieser Anteil sprang zwischen den Erhebungszeiträumen Ende 2023 und 2024 von der Hälfte auf fast 90 % (53 % auf 88 %, Freeman, 2025).

Hochschulen müssen insofern sicherstellen, dass Prüfungsleistungen nicht entwertet und Studierende die produktive Nutzung solcher Tools erlernen. Studierende dürfen einerseits wesentliche kognitive Aufgaben nicht vollständig an GenAI delegieren: Aufgaben und Prüfungsleistungen müssen angepasst werden. Weiterhin entsteht ein neuer Bedarf an Kompetenzschulung, den Studierende wie Unternehmen äußern: der produktive Umgang mit den neuen GenAI Tools muss eingeübt werden. Deutsche Studierende fühlen sich hierauf nicht gut vorbereitet: In der CHE-Studie bewerten sie das bestehende Angebot zum Erwerb von KI-Kompetenzen mit nur 2,7 von 5 Sternen (Hüsch, Marc et al., 2025).

Die zunehmende Verwendung von KI in der Lehre hat gute Gründe. Wie oft eine neue Technologie genutzt wird, hängt nach dem Technology Acceptance Model (TAM, s. Abbildung 1.14) von der wahrgenommenen Benutzerfreundlichkeit (perceived ease of use) und der wahrgenommenen Nützlichkeit (perceived usefulness) ab (Marangunić & Granić, 2015). Generative KI wie ChatGPT decken sichtlich beide Aspekte ab: Sie sind einfach zu nutzen (Kestin et al., 2025; Lee et al., 2025; Monib et al., 2025; Naddaf, 2025) und erzeugen einen deutlichen Mehrwert, wie Studierende und Lehrende in einer Vielzahl von Umfragen der letzten zwei Jahren berichten (Heidt, 2025; Morgan, 2024; Ou et al., 2024). Lehrende ziehen nach: Meta-Untersuchungen zeigen ein extremes Wachstum an Publikationen zur Nutzung von LLM im Hochschulalltag (Ma, 2025; Ogunleye et al., 2024).

Auch außerhalb der Hochschule steigt die Nutzung. Eine Reihe von Studien zeigen erhöhte Produktivität von Büroarbeitenden mit LLM-Unterstützung: der Kundensupport arbeitet 15 % schneller, wenn das Sprachmodell Antwortoptionen vorschlägt und Verweise auf interne technische Dokumentation anbietet (Brynjolfsson et al., 2025), Programmierer programmieren schneller (Peng et al., 2023), Consultants sind produktiver bei komplexen Beratungsprojekten (Dell’Acqua et al., 2023) und Sprachmodelle wie ChatGPT können eine Vielzahl kleiner Aufgaben beschleunigen (Handa et al., 2025-04-08, 2025) und werden insofern gerade zur Texterstellung schon millionenfach als Hilfsmittel im Beruf genutzt: Von Kundenbewertungen über Pressemitteilungen und Stellenanzeigen (Liang et al., 2025).
Schauen wir auf die Abnehmer unserer Graduierten: Wie nutzen die Unternehmen Mitte 2025 solche Sprachmodelle? Eine aktuelle Studie (2025/12) zur Nutzung von GenAI in Unternehmen stellt ein extremes Wachstum fest sowie einen deutlichen Unterschied in der Nutzung von erfahrenen und weniger routinierten Usern (Chatterji, 2025). Der OpenAI-Report zeigt, dass die Nutzung von Sprachmodellen in Unternehmen 2025 deutlich breiter und tiefer wird: ChatGPT-Enterprise-Nachrichten stiegen im Jahresvergleich etwa um das Achtfache, gleichzeitig wachsen wiederholbare Arbeitsabläufe stark (Nutzung von Projects/Custom GPTs ~19-fach seit Jahresbeginn; rund 20 % der Enterprise-Nachrichten laufen bereits über solche strukturierten Workflows). Gleichzeitig bleibt bei fortgeschritteneren Funktionen noch viel ungenutztes Potenzial. Vor allem der Mehrwert von neueren Funktionen wie DeepSearch (Delegation ausführlicher Recherchen), Reasoning (schrittweises, sorgfältiges Antworten mit deutlich höherer Qualität) und Datenanalyse mit Coding Tools wie Codex werden von Praktikern mit Firmen-Lizenz noch sehr selten genutzt. Selbst unter monatlich aktiven Enterprise-Nutzern haben 19 % noch nie Datenanalyse, 14 % noch nie Reasoning und 12 % noch nie (Deep) Search genutzt (bei täglich Aktiven sinkt das auf 3 %, 1 % und 1 %).
1.6 Risiken und Nebenwirkungen
Die Metapher mit dem E-Bike trägt allerdings auch, was die Risiken und Nebenwirkungen angeht: Ab wann lässt die maschinelle Unterstützung wichtige Muskeln verkümmern? Solche Gefahren bestehen – wie empirische Studien zeigen, erfordern die neuen Workflows der Wissensarbeit durch KI-Unterstützung auch neue Formen der kritischen Auseinandersetzung mit den Inhalten.
Wird der Umgang mit GenAI nicht geübt, droht ein Rückgang des kritischen Denkens. Eine Studie von 319 Wissensarbeitern zeigt, dass sich das Gewicht zwischen den Einzelaufgaben der Wissensarbeit mit LLMs verschiebt: Der Aufwand für die Recherchen selbst sinkt, es steigt andererseits der Aufwand für Management-ähnliche Aufgaben: Koordination der Einzelaufgaben für Mensch und Maschine, kritische Prüfung der berichteten Ergebnisse und die Integration von Ergebnissen in den Gesamtprozess (etwa zur Erstellung eines Gesamtberichtes, einer Test-Spezifikation oder eines Protokolls) (Lee et al., 2025).
Im Gegensatz zur einfachen Faktensuche im Internet werden hier nicht nur ein paar dornige Zweige im Aufgabenbündel mechanisch ‚geerntet‘, sondern gleich das gesamte Bündel fertig verschnürt bereitgestellt. Schlimmstenfalls droht das, was ein Artikel von Walsh (2025) prägnant betitelt: „Everybody is cheating their way through college“. Wenn klassische Projektaufgaben quasi auf Knopfdruck erstellt werden können, droht diese Form von Leistung sinnlos zu werden. Mit etwas Lust an Dramatik können wir uns Endzeit-Szenarien vorstellen, in denen Lehrende klagend durch die Trümmer ihrer schönen Portfolio-Prüfungen stolpern: Die Homework-Apocalypse (E. R. Mollick, 2023).
Aber so schlimm muss es nicht werden. Plausible Ansätze, Lehrformate auf die allgemeine Nutzung von GenAI hin umzugestalten existieren bereits. Unser Ziel dabei muss sein, dass erwünschte Schwierigkeiten nach Bjork & Bjork (2011) beibehalten oder sogar verstärkt werden, auch wenn die meisten Studierenden zu Hause starke Sprachmodelle nutzen können.
Wie kann man also verhindern, dass die Studierenden kritische kognitive Aufgaben allein den KI-Systemen übergeben? Lehre heißt in diesem Kontext auch, empfohlene Arbeitsweisen mit der neuen Technik zu üben. Wie das gehen kann, sehen wir in den folgenden Kapiteln.
1.7 Kapitelübersicht
Im folgenden Kapitel werden wir zunächst einige Grundbegriffe (Kapitel 2) klären: Was sind große Sprachmodelle und was ist mit Begriffen wie Token, Prompt und RAG gemeint? Welche Modelle können Lehrende aktuell nutzen und welche Empfehlungen für Prompts sind belastbar? Dann fragen wir nach Zielen (Kapitel 3): Welche Art von Wissen und Methoden unterscheidet und empfiehlt die Lernforschung? Welche didaktischen Wirkmechanismen können durch KI genutzt werden, um typische Probleme der Hochschullehre anzugehen? Im Abschnitt 4 schauen wir auf Praxisbeispiele (Kapitel 4) für vier Anwendungsfelder von Sprachmodellen an Hochschulen: KI als Hiwi (direkte Arbeitserleichterung), KI als Copilot (Unterstützung beim Schreiben und Coden) und KI als Tutor (Feedback und Lernunterstützung) sowie KI als Simulator (Role Play und Goal Play). Abschließend zeigen wir verschiedene Anwendungen von KI in verschiedenen Kurstypen und gehen auf neue Herausforderungen für Prüfungen ein (Kapitel 5). Im Appendix finden Sie eine breite Sammlung von didaktischen Prompts und auf GenAI ausgerichteten Aufgabenstellungen von führenden Hochschulen. Dabei erläutern wir zunächst, wie die Prompts aufgebaut sind (Anhang A) und zeigen dann eine Liste strukturierter Best-Practice Beispiele (?sec-prompts).
1.8 Schlaglichter aus der Forschung mit GenAI: Erfahrungsberichte aus den Disziplinen (GPT-5 und 5-Pro)
Wie und wofür lassen sich die stärksten Sprachmodelle aktuell in der Forschung nutzen? Zum optionalen Abschluss dieses Kapitels finden Sie hier kurze Zusammenfassungen der Ergebnisse aus den verschiedenen Disziplinen (Bubeck et al., 2025).
Forschender: Sébastien Bubeck
Thema: Untersuchung, ob GPT-5 ein kürzlich veröffentlichtes Resultat zur Konvexität von Optimierungskurven verbessern oder reproduzieren kann.
Mehrwert:
„…one can see that GPT-5 claims to have improved the condition from η≤1/L to η≤1.5/L, thus approaching the optimal bound (but not quite getting there) of η≤1.75/L. But is this claim substantiated? It is indeed, and the proof given by GPT-5 is shown in Figure I.2, which the present author has verified to be correct.“
„…the proof given by GPT-5 is quite different from the one in v2. Indeed, the GPT-5 proof can be viewed as a more canonical variant of the v1 proof…“
Probleme:
„GPT-5 did not manage to fully rederive the v2 result, but it basically went half-way between v1 and v2.“
Schlussfolgerungen:
„To say it plainly, such a result (improving from 1/L to 1.5/L) could probably have been achieved by some experts in the field in a matter of hours, and likely for most experts it would have taken a few days. This is the type of science acceleration that we will see time and again in this report.“
Forschende: Mehtaab Sawhney und Mark Sellke
Thema: Nutzung von GPT-5 zur Identifizierung bereits veröffentlichter Lösungen für Probleme aus der Erdős-Datenbank, die dort als „offen“ gelistet waren.
Mehrwert:
„GPT-5 located references solving the above problems… Identifying these decades-old papers required GPT-5 to go far beyond the functionality of a search engine, and indeed to read each of these papers in detail and apply a genuine understanding of mathematics.“
„GPT-5 translated and explained the proofs from [Pom59] to us so that we could verify them ourselves.“
„GPT-5 assisted us in pointing out parts of the paper that made the intended definition clear.“
Probleme:
„…in some cases it was overly enthusiastic about partial progress it had found.“
Schlussfolgerungen:
„GPT-5 therefore provides the practicing mathematician a new mechanism to access the collective breadth of the mathematical literature.“
„This provides a convenient, crowd-sourceable ‘soft certificate’ that the solution is unlikely to appear in the published literature.“
Forschender: Timothy Gowers
Thema: Erfahrungen bei der Nutzung von LLMs für mathematische Probleme im Frühstadium.
Mehrwert:
„…with GPT-5 my experience has been that the references are rarely hallucinated, and even the hallucinations can turn out to be pointers to references that exist and are useful.“
„…GPT-5 has solved them [well-defined subproblems] for me in a matter of seconds.“
„…I have had reasonably precise ideas for solving problems that I have run past GPT-5 Pro, which has explained to me why them cannot work.“
„…even the less good ideas of an LLM can sometimes stimulate me to make progress. (I think of this as the ‘That clearly doesn’t work … but wait a minute!’ phenomenon.)“
Probleme:
„…on the negative side, if I ask more open-ended questions, or offer more sketchy ideas for proof attempts, then that seems to encourage the more annoying characteristics of LLMs to come to the fore: they will tell me that my ideas do indeed work, and will write something that supposedly fleshes out the details but that does not withstand close scrutiny.“
„…it gave me a hallucinated reference but by an author who had written on closely related topics.“
Schlussfolgerungen:
„…my current assessment of LLMs is that they are just beginning to be useful as research collaborators…“
„…LLMs can speed up the process of thinking about a problem, especially if that problem is a little outside one’s primary domain of expertise…“
„…they are capable of playing this knowledgeable-research-supervisor role with me… but that they are not yet at the level… at which a human mathematician… would ask for joint authorship.“
Forschende: Mehtaab Sawhney und Mark Sellke
Thema: Lösung eines offenen Problems über Teilmengen von {1, …, N}, bei denen ab+1 nicht quadratfrei ist.
Mehrwert:
„GPT-5 put forward the new idea that led to our solution…“
„The idea suggested by GPT-5’s reply… gives a method to use any single number b ∈ A to obtain similarly harsh constraints on all other a ∈ A.“
Probleme:
„GPT-5 made attempts in this direction but had numerous errors in its implementation (as can be seen in the transcript).“
„…current models remain limited in perceiving the ‘negative space’ of mathematics. While models are able to suggest plausible proof strategies, they often do not realize certain ‘obvious’ examples which block progress, and are overly confident in the power of existing methods.“
Schlussfolgerungen:
„…GPT-5 has the ability to serve as an effective mathematical assistant, capable of recalling relevant lemmas, identifying analogies and locating relevant results from vague, ill-specified prompts.“
Forschende: Sébastien Bubeck, Mark Sellke und Steven Yin
Thema: Beweis von Ungleichungen für die Anzahl bestimmter induzierter Teilgraphen in Bäumen.
Mehrwert:
„Both of GPT-5’s proofs are quite different from any of the arguments in [BL16; Bub+16].“
„…GPT-5’s proof is short and elegant, and based on a somewhat miraculous identity.“
Probleme:
„A few incorrect proofs were also generated and rejected by human checking.“
Schlussfolgerungen:
„…GPT-5 was able to reprove the first inequality, and then build on this to also prove the second (open) inequality.“
Forschende: Sébastien Bubeck, Mark Sellke und Steven Yin
Thema: Identifizierbarkeit des Parameters w in einem modifizierten präferenziellen Bindungsprozess.
Mehrwert:
„GPT-5 was able to prove that w is indeed identifiable…“
„…this illustrates that GPT-5’s decision to focus on the quantity L(t) is already non-obvious.“
Probleme:
„…when we asked (an unscaffolded) GPT-5 to provide more detail for these latter arguments, it made several false starts… After some human pushback, GPT-5 eventually came up with a correct but unnecessarily complicated proof…“
Schlussfolgerungen:
„While all major proof ideas below are due to GPT-5, a few details of proof writing are human-supplied.“
Forschender: Alex Lupsasca
Thema: (Re-)Derivation nichttrivialer Lie-Punkt-Symmetrien der Wellengleichung in einer Kerr-Raumzeit.
Mehrwert:
„Within 18 minutes, the model produced the correct curved-space generators closing into SL(2, R)…“
„The final generators are too structured to be a lucky guess. The model likely executed (implicitly) a mix of: recognizing conformal invariance in the flat equation, hypothesizing a curved analogue, and/or exploiting a coordinate map…“
Probleme:
„The model initially failed on the curved-space problem, but then succeeded after a flat-space warm-up…“
„What GPT-5 got wrong (along the way). The cold start on Eq. (I.1) incorrectly concluded ‘no symmetries.’“
Schlussfolgerungen:
„AI as a symmetry engine. With minimal domain scaffolding, current models can carry out nontrivial Lie-symmetry discovery for PDEs with non-constant coefficients.“
„Research velocity. Given such capabilities, the time from idea to publishable result can compress from months to days once the right prompts and scaffolds are in place.“
„…contemporary LLMs can act as practical assistants for symmetry discovery and analytic structure mining in theoretical physics.“
Forschender: Brian Keith Spears
Thema: Entwicklung eines reduzierten physikalischen Modells für thermonuklearer Brandwellen in ICF-Kapseln.
Mehrwert:
„GPT-5 is quite good at this kind of model development and setup. It required little intervention on my part to make this plausible and complete.“
„The point is that I can now deliver in minutes as if I were at the highest level I have ever been at for this kind of work. … to have it in minutes is remarkable.“
„However, when re-prompted to examine a pathological result or null signal, GPT-5 offered quite sophisticated solutions, including different implementations of FFTs to prevent aliasing, improved resolutions to track burn fronts…“
Probleme:
„GPT-5 was a bad designer, offering results that were null, noisy, or invalid (NaNs), while claiming that glory had been achieved.“
„The model, in its eagerness to please, often introduces numerical duct tape to smooth over a thorny issue, silently swaps out detailed numerical solves for approximations with trends it knows I want, and confidently declares victory when numerical signals are still obviously noise.“
Schlussfolgerungen:
„…executing this workflow from concept, to numerical exploration, to theoretical supporting statement in hours is rather amazing.“
„I feel like my 6 hours of work here yielded something I could have done over a month or two with a very good pair of postdocs… That is a compression of about a factor of 1000.“
„…users must be expert enough to catch the oversimplifications, must persist to get the model to reconsider, and must be vigilant…“
Forschender: Robert Scherrer
Thema: Analytische Integration des Leistungsspektrums von Garfinkle-Vachaspati-Strings.
Mehrwert:
„After reasoning for 40 minutes, GPT-5 Pro produced a result for large odd n identical to the asymptotic result I had previously derived… It used a completely different method of solution from my own.“
„GPT-5 Pro also gave the leading order correction term to this formula… I was not aware of this correction term…“
Probleme:
„The program hung up for quite a long time, giving me no details about its thought process. After several hours I became frustrated and killed it.“
Schlussfolgerungen:
„GPT-5 Pro is capable of solving complex analytic integrations that are beyond the reach of symbolic manipulation programs such as Mathematica.“
Forschender: Derya Unutmaz
Thema: Mechanistische Analyse der Wirkung von 2-DG auf die Differenzierung von T-Zellen und Vorhersage der Zytotoxizität von CAR-T-Zellen.
Mehrwert:
„GPT-5 Pro provided the key mechanism that could explain these findings and, in addition, made highly relevant experimental suggestions.“
„The mechanistic insight and further hypothesis to dissect these findings were highly valuable and not immediately obvious, despite our deep expertise in this field.“
„GPT-5 Pro perfectly analyzed and described the data in the figure…“
„…GPT-5 Pro made sufficient contributions to this work to the extent that it would warrant its inclusion as a co-author in this new study.“
Probleme:
„…a caveat for this suggestion is that GPT-5 Pro may have known about this finding and made the connection with this result.“
Schlussfolgerungen:
„GPT-5 Pro can function as a true mechanistic co-investigator in biomedical research, compressing months of reasoning into minutes, uncovering non-obvious hypotheses, and directly shaping experimentally testable strategies.“
„Precision interpretation of complex biology. GPT-5 Pro rapidly connected the observed phenotypes to a mechanistic hypothesis…“
„The net effect will be a much higher discovery rate per experiment and a shorter route from observation to discovery to intervention, thus profoundly accelerating the biomedical scientific process.“
Forschender: Nikita Zhivotovskiy
Thema: Suche nach Anwendungen und verwandter Literatur für eine neue geometrische Aussage über „α-ratio covers“.
Mehrwert:
„…given only a core mathematical statement, GPT-5 can rapidly surface nontrivial and technically aligned links across areas… providing context for new applications.“
„At first sight… this seems unrelated to Theorem II.1.1 and could be mistaken for a hallucination. However, unpacking their proof shows that their result can be phrased as a coordinatewise (1+ϵ)-ratio cover…“
Schlussfolgerungen:
„…GPT-5 can rapidly surface nontrivial and technically aligned links across areas… providing context for new applications.“
Forschender: Christian Coester
Thema: Verbesserung der unteren Schranken für das Problem des „Convex Body Chasing“.
Mehrwert:
„Given a single short prompt, GPT-5 produced a rather non-obvious counter-example against the algorithm.“
„GPT-5 suggested a much simpler and cleaner solution: trigger the switch once the algorithm is below the semicircle at distance ≥ ε from pt. This avoids the freeze… The idea seems obvious in hindsight, yet far more elegant…“
„…the inspiring appearance of the number π/2 in its reasoning trace…“
Probleme:
„The argument it gives for this [feasibility of the construction] is actually incorrect, but a correct argument is easy to see…“
„…it initially failed to understand how viewing the problem in continuous time could yield stronger bounds, and upon later attempts… it presented arguments containing serious flaws.“
„…GPT-5’s responses also contained some errors, but these were easy to fix for a human, overall accelerating the research process.“
Schlussfolgerungen:
„Perhaps the most impressive part is its proof refuting the follow-the-leader algorithm, produced from a single prompt without any guidance on how to approach the task.“
Forschende: Venkatesan Guruswami und Parikshit Gopalan
Thema: Suche nach einer unteren Schranke für die Co-Dimension von Codes, die Clique-Indikatoren vermeiden.
Mehrwert:
Kein expliziter Mehrwert im Text außer der Reproduktion bekannter Beweise.
Probleme:
„Initially, it was convinced that this bound was tight (up to an additive constant), and tried to convince us of this using a sequence of buggy arguments, resorting to linear algebra and proof by authority…“
„The most amusing was a hallucinated response to the effect that one of us had asked this question on TCS Stack Exchange… Both these claims are incorrect.“
„…it appears that GPT-5 reproduced Alon’s proof and passed it along to us without realizing its source.“
Schlussfolgerungen:
„Our experience illustrates a pitfall in using AI: although GPT-5 possesses enormous internal knowledge… it may not always report the original information sources accurately. This has the potential to deceive even seasoned researchers into thinking their findings are novel.“
Link zurück zum Fließtext: Siehe 1.11